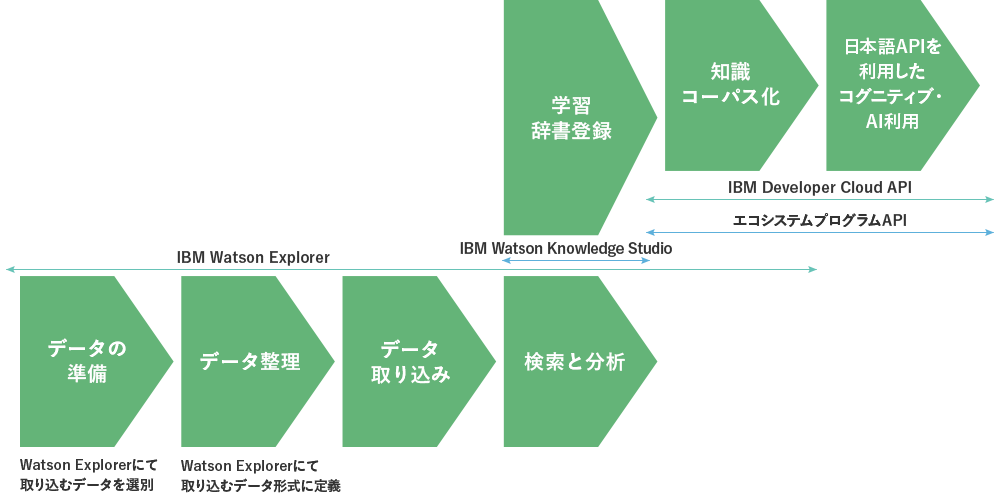
課題解決のためのサービスを提供
-

収集したログや情報があるけれど
情報量が多すぎて運用しきれない -

リソースが限られていて
分析や解析に時間がかかる -

分析ツールはあるけれど
動向や傾向がわからない
膨大な量のSNSやお客様の声データ分析
SNSデータ、アンケートデータ、お客様の声データ…などの情報資産はあるが、エクセルで管理しているだけでうまく活用できていない。
エクセルの機能にも限界があり、本当に欲しい情報を見落としてしまっているのではないか?
課題
- 多数のベクトルの異なるカテゴリー分けがなされた、膨大な情報を保有している
- カテゴリーを組み合わせて、2軸でデータ分析・抽出をしたい
- データを深掘りして、新たな事業計画や広告戦略などにデータを役立てたい
MIWで解決
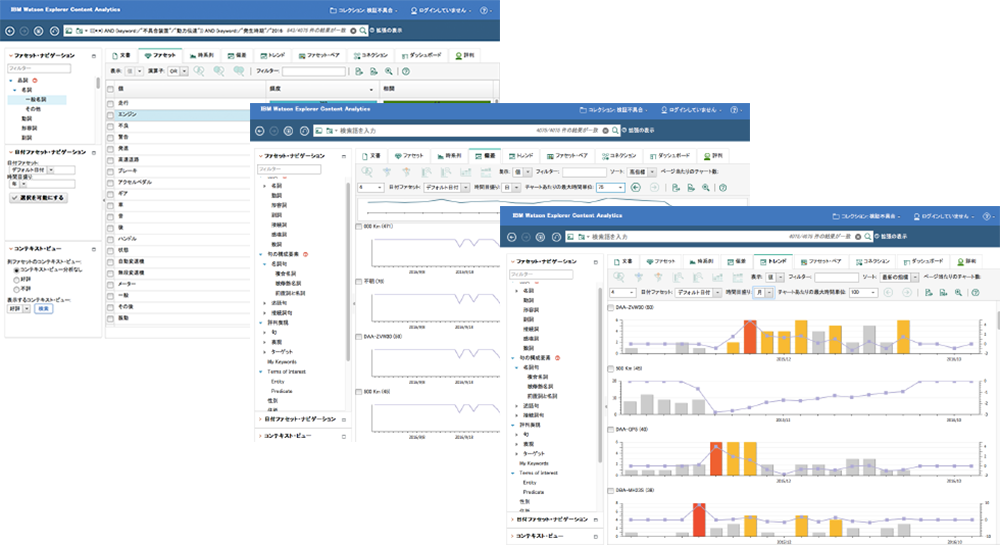
複数カテゴリーを持つビックデータも、MIWのACサービスを利用することで、分析目的に合わせたデータの抽出が可能です。
エクセルでは抽出できなかった、2軸を掛け合わせたデータ分析だけでなく、キーワードの時系列分析や、キーワード同士/カテゴリー項目間での相関関係、SNSデータを用いたトレンド分析、お客様の声を用いた評判分析など…多種にわたる高機能分析が1つのサービスで、さらに、月額でご利用いただけます。
簡単な操作で商品、サービス改善につなげるレビュー分析
ECサイトを運営しており、レビューデータも溜まってきたが、どうやって分析をしてデータを活用すれば良いかわからない。AIのテキストマイニングは、とにかく難しそうで導入を躊躇してしまっている。そもそも、テキストマイニングは何ができるのかイメージがつかない。
課題
- レビューサイトで自社商品のレビューを行いたい
- レビューを元に自社サービスの改善につなげたい
- 製品やサービスの改善につながる情報を探すのに時間がかかるを改善したい
MIWで解決
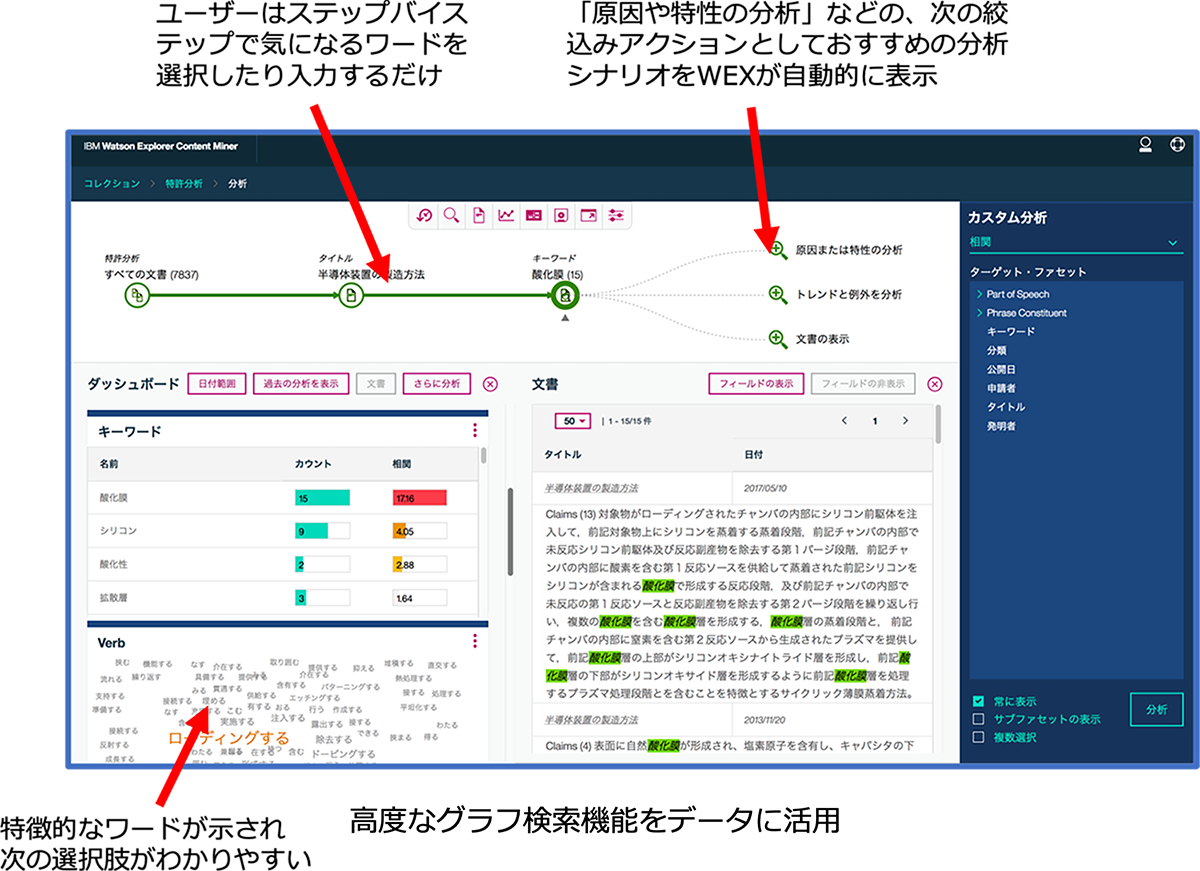
機械学習機能(AI)対応のテキストマイニングツールであれば、教師データ(マスターとなるデータ)を登録/学習させることで、AIが自動でラベル付をしてくれるため、視覚的に情報の確認/抽出が可能となります。また、次の分析ステップをアシストしてくれるため、分析操作やテキストマイニングツールの利用が初めての方も、簡単にデータ分析ができす。アシスト通りにステップを踏むことで容易に深掘り検索ができるため、これまで見出せなかった分析結果への到達が期待できます。
不完全な業務日報データの分析
従業員が業務として様々な記録やログを基幹システムに入力しているが、入力業務が圧迫し欠損した入力欄があったり、また、入力データの確認も徹底されていないため歯抜け状態のデータが出来上がってしまっている。
このデータを資産にするためには、歯抜け状態を脱却したいが、一つ一つ埋めていくのは困難だ。
課題
- 膨大な量のデータが基幹システムで管理されているが、歯抜け状態でDBとして活用できるデータではない
- 欠損/歯抜け箇所があっても、テキストマイニング(分析)できるツールを探している
MIWで解決
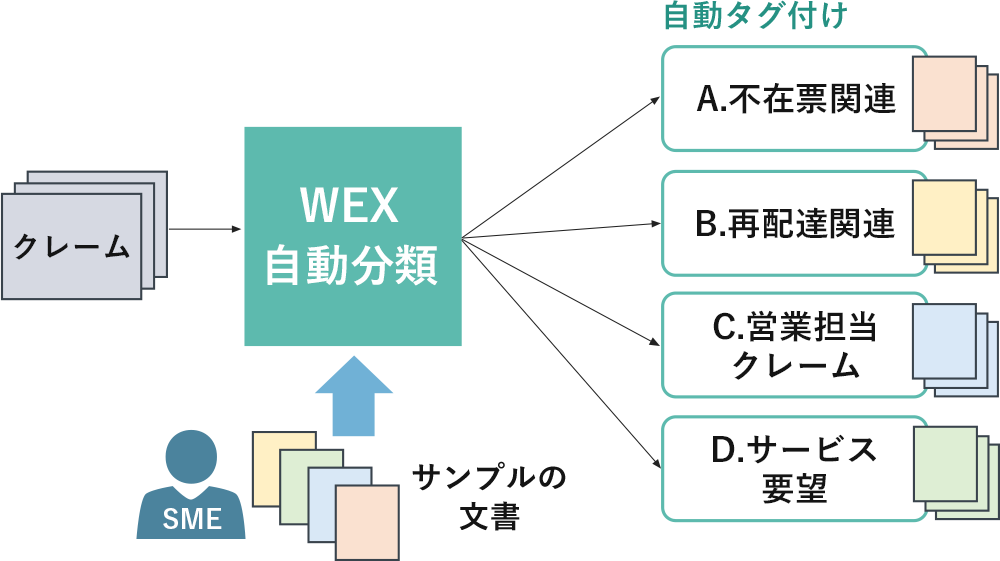
機械学習機能(AI)により、データが歯抜けの状態であっても文書の自動分類が可能です。分類機に登録された文書データを、AI が自動で構造化し自動分類機(機械学習モデル)を自動で構築します。この機械学習モデルを活用することで、定義されたカテゴリーを予測したり、予測結果としてラベルを割り当てる、などの自動分類を実行します。
完璧でない状態そのままでデータを資産化することが可能です。